< Tensorflow >Tensorflow2.4 最佳实践
开始
最近想尝试一下用Transformer做图片分类的效果,于是就在网上找找有没有比较好的例子.发现keras官方有个例子,于是就clone下来看看.本以为multi-head-attention这个模块需要自己来实现,竟然发现tf.keras中已经实现了multi-head-attention的接口,发现是真的方便(tensorflow的最新版本tf2.4才有的一个接口).
最近想尝试一下用Transformer做图片分类的效果,于是就在网上找找有没有比较好的例子.发现keras官方有个例子,于是就clone下来看看.本以为multi-head-attention这个模块需要自己来实现,竟然发现tf.keras中已经实现了multi-head-attention的接口,发现是真的方便(tensorflow的最新版本tf2.4才有的一个接口).
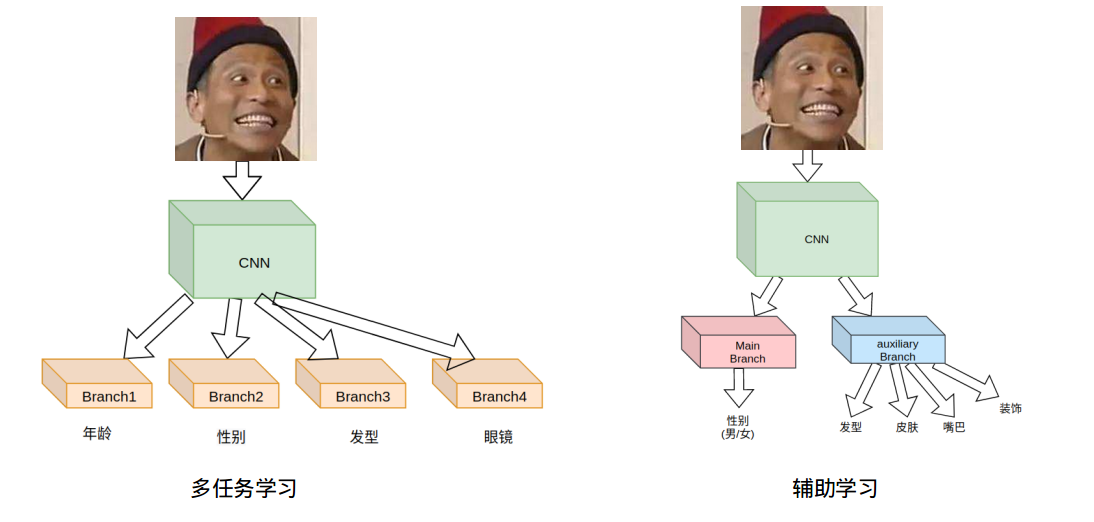
端到端的深度神经网络是个黑盒子,虽然能够自动学习到一些可区分度好的特征,但是往往会拟合到一些非重要特征,导致模型会局部坍塌到一些不好的特征上面。常常一些人们想让模型去学习的特征模型反而没有学习到。为了解决这个问题,给模型加入人为设计的先验信息会让模型学习到一些关键的特征。下面就从几个方面来谈谈如何给模型加入先验信息。
来自于2020年1月份的一篇arxiv文章.文章的主要思想是通过给CNN网络(以分类模型举例)的输入图加入噪声来使得模型更加的鲁棒.
与之前手动加入噪声不同的是,该文章采用对抗网络的思想,通过一个噪声生成器来生成噪声,并尽量使你的分类模型(判别模型)做出错误的分类.
而你的分类模型的目的是尽量能够不被加入的图片噪声干扰,依然能做做出正确的输出.最终经过数轮的迭代训练,达到使得你的分类模型能够抵抗各类噪声干扰的目的.
1 | S_a1(q_a1 + Z_a1) = S_w1(q_w1 + Z_w1) * S_a0(q_a0 + Z_a0) |
q_a1: Quanted activation value in layer 1
S_a1, Z_a1: Estimated scale and zero point in layer 1
q_w1: Quanted weight in layer 1
S_w1, Z_w1: Statistical scale and zero point in layer 1
q_a0: Quanted activation value in layer 0
S_a0, Z_a0: Estimated scale and zero point in layer 0
As we can see, in order to compute q_a1(Quanted activation value in layer 1), we have to get S_w1, Z_w1, S_a0, Z_a0, q_a1, Z_a1. To get S_w1/Z_w1 is simple, we can get the Statistical maximum of the weights in each layer we want. The only tricky thing is how to get S_a1/Z_a1/S_a0/Z_a0, which have to be estimated from the training data.

As we all know, support vectors is a notation in SVM(Support Vector Machine). Support vectors means that the data points in the decision boundary(the Maximum Margin in SVM) are very important in a classification algorithm.
We can train a SVM only with the ‘Support Vectors’ and can achieve the same accuracy with models trained with more data. So does the ‘Support Vectors’ exists in DeepLearning?
For multi-class classification, if you want optimize only one category during training, you should use SOFTMAX cross entropy. Otherwise, if you want to optimize more than one category, you should use SIGMOID cross entropy.