< Deeplarning > Understand Backpropagation of RNN/GRU and Implement It in Pure Python---1
Understanding GRU
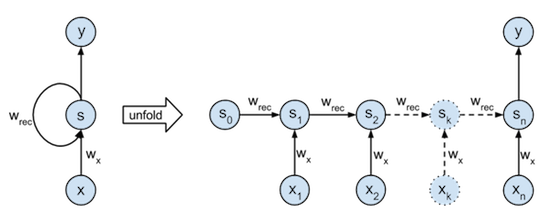
As we know, RNN has the disadvantage of gradient vanishing(and gradient exploding). GRU/LSTM is invented to prevent gradient vanishing, because more early information could be encoded in the late steps.
Just similarly to residual structure in CNN, GRU/LSTM could be treated as a RNN model with residual block. That is to say that former hidden states is identically added to the newly computed hidden state(with a gate).
For more details about GRU structure, you could check my former blog.