< Tensorflow >Tensorflow2.4 最佳实践
开始
最近想尝试一下用Transformer做图片分类的效果,于是就在网上找找有没有比较好的例子.发现keras官方有个例子,于是就clone下来看看.本以为multi-head-attention这个模块需要自己来实现,竟然发现tf.keras中已经实现了multi-head-attention的接口,发现是真的方便(tensorflow的最新版本tf2.4才有的一个接口).
跑了一个官方给的cifar的例子,效果还行.于是就打算在自己的数据上跑跑看效果,在这个过程中,发现官方给你例子还远远达不到训练速度最优化的程度.于是就把官方例子就改了一下,最终达到了一个满意的训练速度,本篇就是记录一下tf2.4下的训练性能调优全过程.最终调优后的代码会共享出来.
单卡到多卡
官方给的vit(Vision Transformer)的例子是基于单卡的,但是现在训练大型网络已经离不开多卡,于是把官方例子改成多卡训练的版本(这里主要说明一下单机多卡的设置).
首先根据你手上卡的数量来建立一个strategy的对象.
1 | physical_devices = tf.config.list_physical_devices('GPU') |
这里tf.config.experimental.set_memory_growth的作用是限制显存的使用.
然后我们要把数据做一个副本化的包装:
1 | train_dist_dataset = strategy.experimental_distribute_dataset(train_dataset) |
然后我们需要对train_step和test_step做一个封装:
1 | with strategy.scope() |
最后在train_step,test_step,和计算loss和accuracy加上strategy的scope(这里只是拿train_step和test_step举例):
1 | with strategy.scope(): |
经过了上述的步骤,成功的在tf2.4下,把单卡训练转换到了单机多卡训练.
eager mode 到 static graph mode
由于tf2.x模式的执行方式是急切执行(eager mode),eager mode的好处在在于方便debug,但是如果拿来训练就不太好了,因为eager mode会托慢速度.所以我们需要在调试好网络之后把执行模式切换为静态图的模式.而这个步骤非常简单,加上一个tf.function的修饰符就好.
1 | with strategy.scope(): |
调整tf.data数据流顺序
tf.data的数据处理顺序非常重要,改变顺序可能会极度的托慢训练速度.
这里,我的数据处理流程如下:
- 读取所有图片的路径和对应的label.
- 把图片路径给parse成图片.
流程其实很简单,但这里要涉及到几点:
- 如何shuffle.
- 哪里设定epoch
- 哪里设定batch
- 哪里设定预取prefetch.
先来上code,再解释:
1 | image_roots, labels = generate_fileroots_labels(file_root) |
首先,repeat表示需要把数据重复多少次,也就是设定的epoc,shuffle代表在多少的buffer中打乱数据.这两者需要放到map前面,因为在map前,数据流处理的都是图片路径和label的轻量化数据,这对于repeat和shuffle是有利的.
而batch和prefetch就需要放到map的后面.这里需要注意,要先设定batch,再prefetch(不然会慢).
大杀器--tf.profiler
当我们觉得已经把加速做到极致了之后,我们需要用tensorflow自带的性能检测工具tf.profiler来检查一些性能还有那些可以榨取的空间.
用tf.profiler之前,你需要先按照官方的教程安装.这里有个小坑,因为tf.profiler需要依赖libcupti这个库,而libcupti这个库不在cuda的主库目录里,而是在extras/CUPTI/lib64里面,这个需要注意.
然后在你的训练代码中,需要添加如下的code:
1 | for t_step, x in enumerate(train_dist_dataset): |
这个代码段的意思是,在训练的第200步到第300步需要记录你的训练profile.
这里说明两点:
第一,我们不需要要整个训练过程都记录profile,因为记录profile仅仅是为了调优,只需要记录某些步的profile就可以提供你来调优即可.
第二,不从第0步就开始记录是因为我们需要先让训练达到稳定之后记录才会比较准确(示例中是从500步到600步开始记录profile).
好了,我们看一下,都记录了一些什么东西:
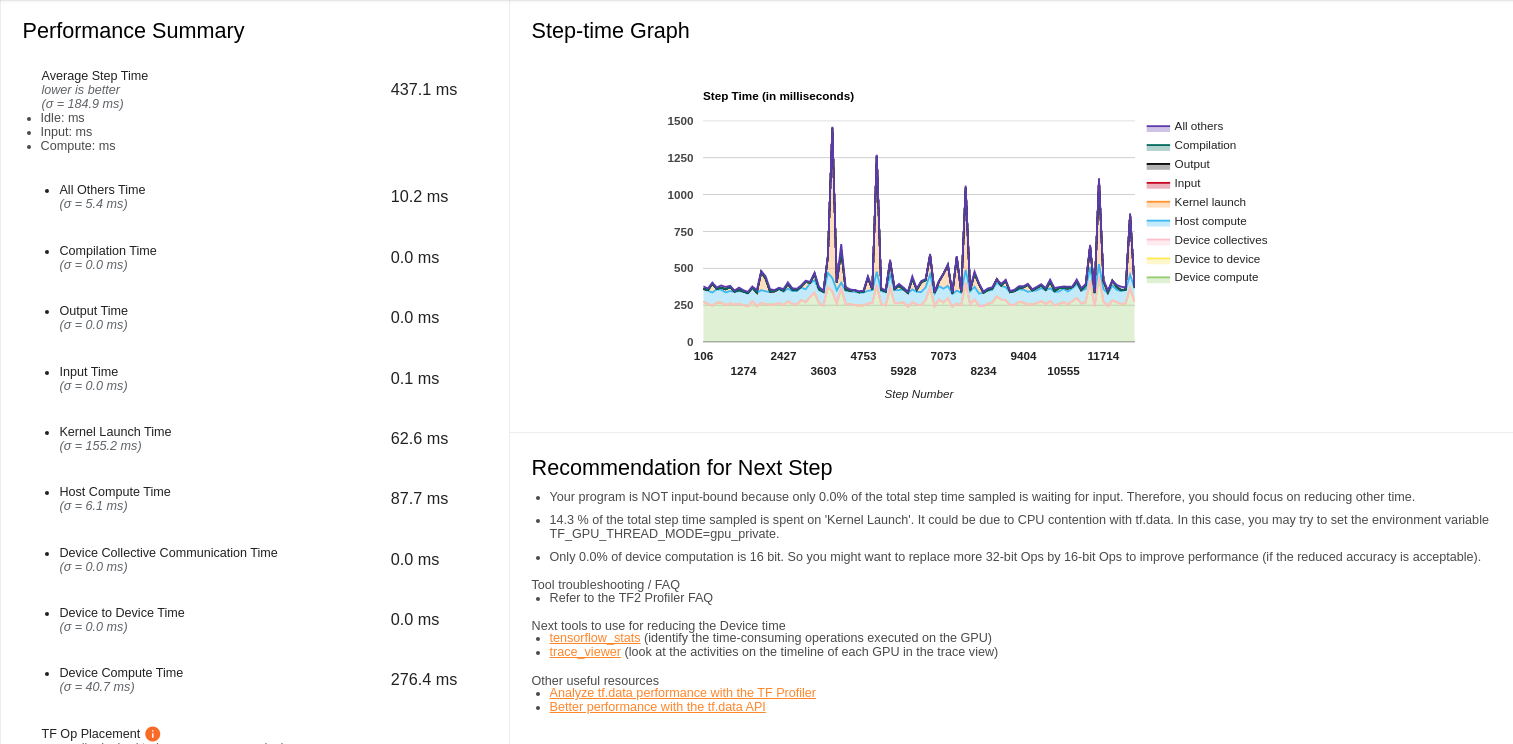
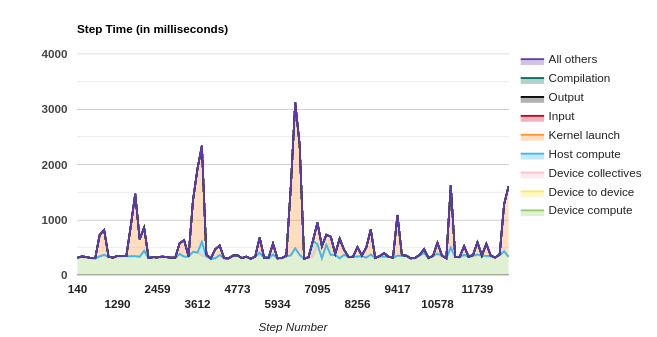
这里我们可以看到耗时主要在3个方面:
- Kernel Launch Time
- Host Compute Time
- Device Compute Time
我们来一个一个解决,首先来解决kernel lanuch time,这个在右边的建议(Recommendation for Next Step)有说明:
- 14.3 % of the total step time sampled is spent on ‘Kernel Launch’. It could be due to CPU contention with tf.data. In this case, you may try to set the environment variable TF_GPU_THREAD_MODE=gpu_private.
也就是说可以通过设定TF_GPU_THREAD_MODE=gpu_private来解决.也就是说要在之前训练程序的前面加上下面一句命令:
1 | export TF_GPU_THREAD_MODE=gpu_private |
然而我这样执行之后发现作用好像不是很大,知道怎么解决的同学可以交流.
我们现在来解决第二个主要耗时的点,也就是Host Compute Time耗时过高.
我们知道,tensorflow的多卡策略是ps-worker的方式,这个ps可以认为是host,主要是负责更新参数和处理数据流,按理说这部分的耗时不应该很高才对.于是我往下看具体的host的耗时的页面:
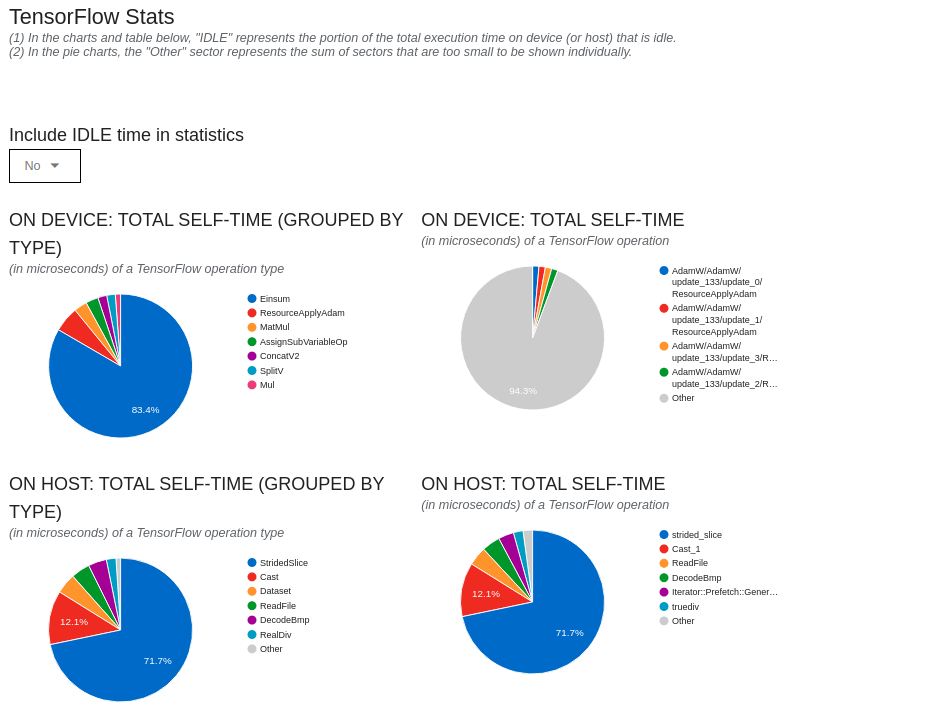
我们看到,host的耗时,很大的程度和2个op有关:
- stridedSlide
- cast
其中stridedSlide占了绝对的大头,经过查阅资料发现,stridedSlide耗时比较高主要和tf.distribute.MirroredStrategy这个对象有关.
因为我在我的工程里面用到了tf.data.Dataset.from_tensor_slices这个对象,这个对象用到了stridedSlide这个操作,而tf.distribute.MirroredStrategy对stridedSlide的操作支持的不好.
网上的建议是把tf.distribute.MirroredStrategy换成tf.distribute.experimental.MultiWorkerMirroredStrategy.
也就是如下实现:
1 | # TRAIN_GPUS = [0,1,2,3] |
更换了之后,果然Host Compute Time 得到了下降.
关于cast这个操作,是因为我在dataset的parse_function里面用到了tf.cast的操作,我把这个操作放到了网络里面,这部分的耗时也消除了(其实是分给worker了).
关于Device Compute Time这一部分,我发现这个部分主要的耗时用到了矩阵操作Einsum上,这一部分的操作也是MultiHeadAttention的主要操作,于是也就没有修改这个部分.
最后
当然,说了这么多,不如大家来下面一行代码来的方便…..
1 | import torch as tf |
不过话说回来,tensorflow和pytorch不是二选一的问题,而是大家最好都会用,这样才能更好在深度学习里探(lian)索(dan).
最后把示例代码放到这里,大家自行取用.
< Tensorflow >Tensorflow2.4 最佳实践