< NCNN-Lession-3 > 读取网络的proto信息
开始
今天我们开始第三课,来说一些如何读取网络的proto信息,所以我们又要插上一个小红旗:
今天的讲解和之前的不太一样, 之前的都是讲类的实现.今天更加侧重讲解函数处理流程.让我们开始吧。
作用
当我们要把训练好的网络部署到移动端的时候,网络结构的表达就非常重要.因为部署框架需要把你的网络结构读取它的自己的数据结构中.
我们上一节讲的Net/Layer/Blob就是ncnn自己的网络数据结构,所以我们要把自己的模型的网络结构load到ncnn的Net/Layer/Blob中.
我们先用一个例子来看一下ncnn读取的是怎样的网络结构(把它称为proto):
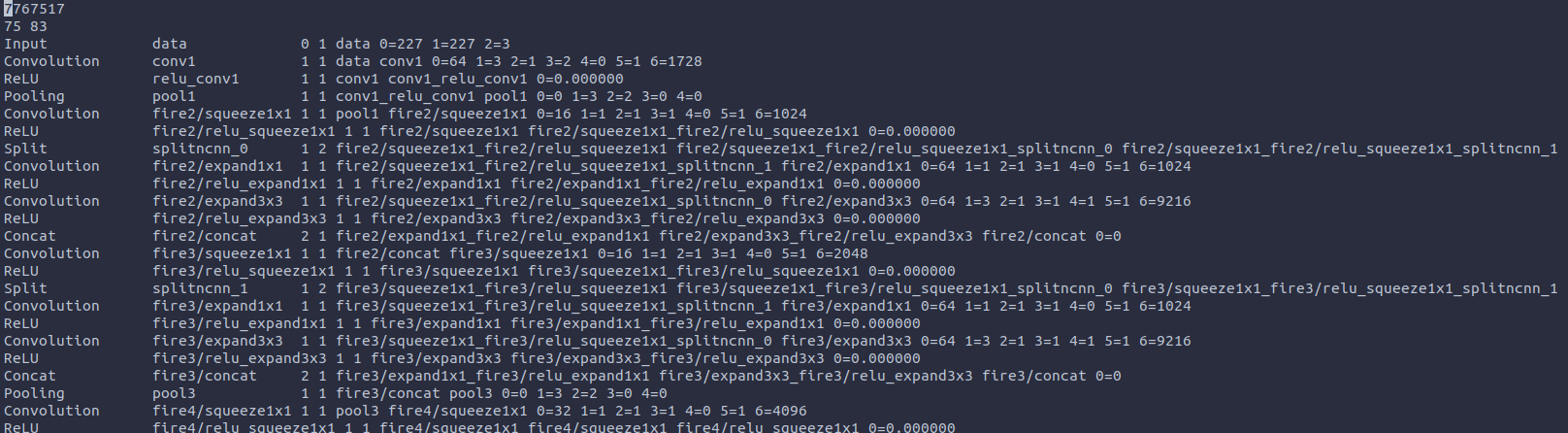
这是一个经典的squeezenet的网络结构(非全部),我们可以看到,第一行只有一个数字,它没有任何意义,只是一个标记,然后第二行有两个数字,分别代表layer的总数和blob的总数。从第三行开始的每一行代表一个网络的layer op操作和对应的layer信息。我们以卷积层为例子,来说明每一列代表什么含义:
| layer_type | layer_name | bottom_count | top_bount | bottom_name | top_name | 参数1 | 参数2 | … |
|---|---|---|---|---|---|---|---|---|
| Convolution | data | 1 | 1 | data | conv1 | 0=227 | 1=225 | … |
| Relu | relu_conv1 | 1 | 1 | data1 | conv1_relu_conv1 | 0=0.00000 |
其中
- layer_type:这个layer op是哪种op
- layer_name: 这个layer op的名字
- bottom_count: 输入blob的个数
- top_bount: 输出blob的个数
- bottom_name:输入blob的名字
- top_name:输出blob的名字
- 参数: 该layer op的参数
这样的一个proto可以完备的表达一个网络的数据流向, 所以我们可以用它来描述自己的网络结构.我们现在先不讲知道这个proto是怎样来的,今天主要要研究一下ncnn是怎样把这个proto给读到自己的数据结构中.
实现
要把网络的proto读到ncnn自己定义的Net/Layer/Blob中,就要用到我们之前第一课中学习到的datareader类,因为网络proto中都是一些固定格式的信息,所以我们主要用到datareader类中的scan函数,这个其实就是fscan的一种包装,它比较适合读一些结构化的数据。
我们可以把proto中的信息分成3类:
字符串如layer_type, layer_name, blob_name
数字如layer_num, blob_num
带有”=”的参数信息
我们要通过不同的format格式去读取上述三种信息,对应的方式如下:
对于字符串的话,我们需要用如下的方法去读:
1 | FILE* fp; |
注意,我们规定读取字符串的最大长度为256,如果你的字符的长度大于256,则会出现错误.同时,由于函数fscanf遇到空格对停止读取操作,所以不必担心256过长.
对于数字的话,由于不确定数字的写法(比如是否是用科学计数法),我们还是需要用读字符串的方式去读,然后再转化为数字,如下所示:
1 | FILE* fp; |
如上所示,我们需要先判断读取的字符串是不是float,如果是float,我们需要先将其转化为float,如果不是float,我们直接调用sscanf去读取字符串的数字.
对于带有”=”的参数信息,我们需要用如下的方式去读:
1 | FILE* fp; |
给layer和blob分配id
由于后面在前向推理的时候,我们要通过id去找对应的layer和blob,所以给layer和blob分配id就是一件非常重要的事情.
对于layer的id是非常自然的,因为在你的proto中,从第三行开始的每一行都是一个layer op的操作,所以我们就根据行数,给每一个layer顺序的分配自己的id.
给blob分配id的思想类似,在前面我们介绍过,每一层layer信息中,有一个参数代表着这个layer的top个数,我们可以根据layer的id和top的个数给blob分配id信息.
layer类还有两个重要的参数,那就是layer->tops和layer->bottoms,前者是layer的top blob的id的集合,后者是layer的bottom blob的id集合.
我们在赋值layer->tops的时候可以直接用blob的id.我们在赋值layer->bottoms的时候,就需要从之前的blob中去找对应的名字的blob的id,这也就是我们需要blob的name的原因.
具体的代码可以如下所示:
1 | int blob_index = 0; |
有一个小trick需要说一下:
由于我们需要频繁的调用如下的函数接口:
1 | dr.scan(format, buf); |
我们可以通过宏函数来调用这个函数,这样就会比较简单明了:
1 | #define SCAN_VALUE(fmt, v) dr.scan(fmt, &v); |
代码示例
关于这一节的测试程序在这里,代码结构如下:

大家可以看到,我们这里多了一个paramdict的实现,这是由于在读取数字的时候,涉及到判断是否是float,和char转float等等操作,会比较繁琐,所以ncnn把这部分的实现放到了paramdict这个类去实现.
< NCNN-Lession-3 > 读取网络的proto信息