< Deeplarning > Understand Backpropagation of RNN/GRU and Implement It in Pure Python---1
Understanding GRU
As we know, RNN has the disadvantage of gradient vanishing(and gradient exploding). GRU/LSTM is invented to prevent gradient vanishing, because more early information could be encoded in the late steps.
Just similarly to residual structure in CNN, GRU/LSTM could be treated as a RNN model with residual block. That is to say that former hidden states is identically added to the newly computed hidden state(with a gate).
For more details about GRU structure, you could check my former blog.
Forward Propagation of GRU
In this section, I will implement my pure python version of GRU forward propagation. Talk is cheap, show you the code:
1 | def forward(self, x, prev_s, W,Wb,C,Cb, V, Vb): |
As you can see, we firstly concatenate ‘hpre’ and ‘x’ together, and then multiply with weight ‘W’(Equal to ‘hpre’ and ‘x’ separately multiply with its weight and then add together).
Variable ‘r’ and ‘u’ are two gates. Gate ‘r’ controls how much hidden state could be mixed with ‘x’. Gate ‘u’ controls how much hidden state information could be directly flow to the next state.
Back Propagation of GRU
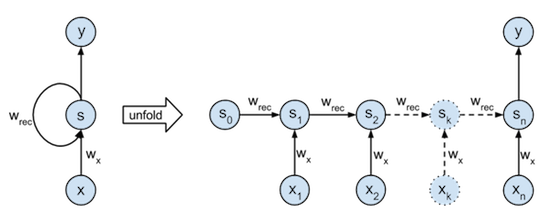
As we know, RNN uses back propagation through time(PBTT) to compute gradients for each time step. PBTT means the gradients should flow reversely through time. The bellow code snippet shows how the gradients flow inside the GRU structure at each time step:
1 | def backward(self, x, prev_s, W, Wb, C, Cb, V, Vb,diff_s, dmulv): |
Here I have admit that to write a back propagation algorithm is a fussy thing, for you should carefully compute the gradients flowing through each operations without any error.
There are some notes for you.
Firstly, while hidden state is used three times in the forward propagation(First branch: compute gate ‘r’ and gate ‘u’. Second branch: to mix information with input ‘x’. Third branch, identically add to the final hidden state), so you should add each gradients of hidden state computed from each branch**(A way to prevent gradient vanishing)**.
Second thing to remember, feed your computed final gradients of hidden state to your last time step(or last layer of your model).
< Deeplarning > Understand Backpropagation of RNN/GRU and Implement It in Pure Python---1